Recovery Post-Crash
Concept. An abort undoes one transaction while the database keeps running; a crash forces that same rollback on every transaction that never committed. Recovery handles it in two passes over the WAL. The forward pass replays every logged row top to bottom, exactly as it first happened: the original writes and any abort (undo) rows already in the log alike. It is not redo-only; it just repeats history. This rebuilds the exact state the database held at the crash, and along the way recovery tracks which transactions reached COMMIT. The backward pass then walks up the log and undoes every transaction that never committed. The database ends fully consistent and ready for new traffic.
Intuition. When the server crashes mid-rush, the log shows Mickey, Minnie, and Daffy were all mid-Premium-purchase. The forward pass replays all three in case their account-table pages never flushed, and notes that Mickey and Minnie COMMITted but Daffy did not. The backward pass then reverses Daffy's charge, because his transaction never finished. Mickey and Minnie stay Premium, Daffy is refunded, and the database is back online.
Recovery on One Log: Down, Then Up
The whole algorithm fits on one write-ahead log. Start state A=10, B=20, C=30, D=40, E=50, update function f(x) = x * 1.2. Five transactions run, then the server crashes.

Figure 1. Recovery as two passes over one log:
- REPLAY (down): re-apply every row exactly as it happened, redos and undos alike, to rebuild the state at the crash.
- UNDO (up): then undo every transaction that never committed, reversing its writes newest-first.
The undone rows are scattered, not a trailing block: T4 even commits late, after T3's writes, yet survives. What gets undone depends on commit status, not position in the log.
Why down before up. After a crash you cannot tell which data pages reached disk, so there is no consistent state to roll back from yet. The forward pass replays the whole log first and rebuilds the exact state at the crash, a known starting point. Only then does the backward pass peel off the transactions that never committed. Run the other way, undoing against half-written pages, and the result is undefined.
No separate analysis pass. You might expect a first pass just to work out who committed. You do not need one. As the forward pass reads the log, it keeps a small in-memory table of every live transaction and marks each one committed when it meets that transaction's COMMIT. By the time it reaches the crash, the table already names the transactions that never committed, exactly the ones the backward pass undoes. The tracking is free, built along the way. (Checkpoints are the one case where it needs its own scan, see Optimizations below.)
The Physical Picture: RAM vs Disk
The two passes work on the log. Here is what is physically happening to the data across the crash.
Just Before Crash

Figure 2. The system an instant before the crash: committed and uncommitted changes coexist, some already flushed to disk, some still only in RAM.
Just After Crash

Figure 3. Just after the crash. Buffer flushes saved some changes, some committed work vanished with RAM, and some uncommitted work sits on disk. The WAL sorts this out.
After Recovery
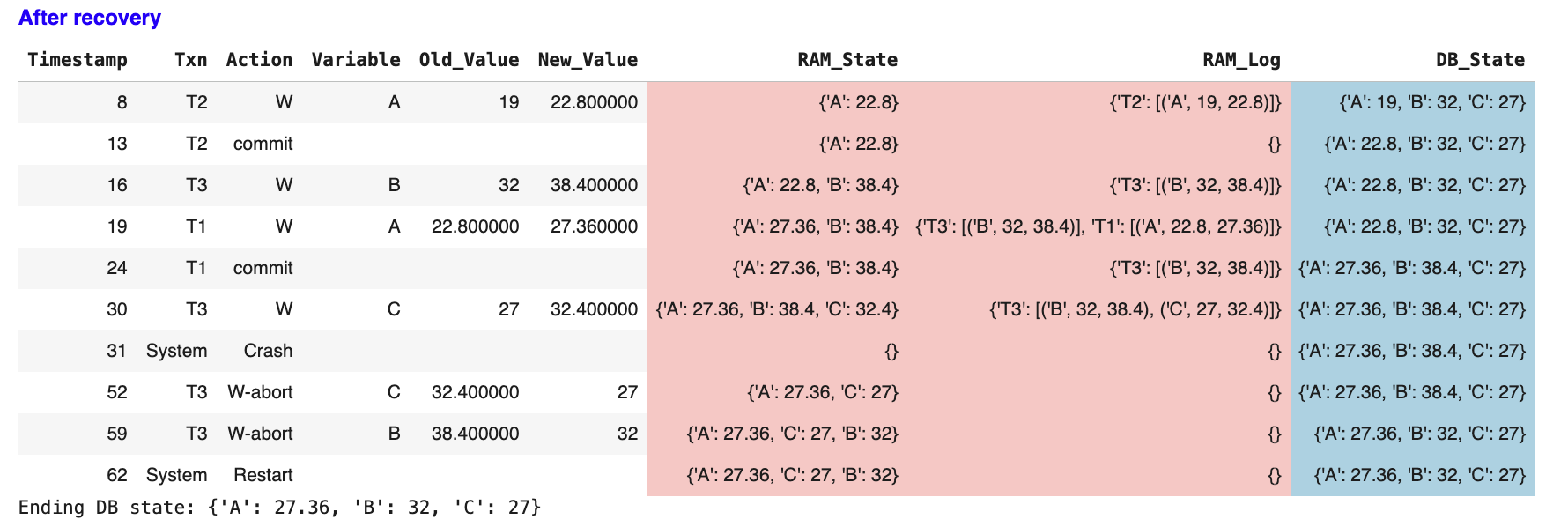
Figure 4. After recovery: the forward pass reapplied every committed change and the backward pass removed every uncommitted one. The database is consistent and ready for new transactions.
Why this works: the WAL is the source of truth. It holds the full history with both old and new values, written durably before any data page changes, so even a corrupted database can be rebuilt from it.
Recovery Guarantees
Recovery restores the ACID guarantees across a crash: committed work survives (durability), unfinished work vanishes (atomicity), the rules hold (consistency), and rerunning it lands on the same state (repeatability). That safety is not free.
What Recovery Costs
-
Time: Can take minutes to hours for large databases.
-
I/O: Must read the WAL since the last checkpoint.
-
Availability: Database offline during recovery.
-
Complexity: Requires careful implementation.
Optimizations
Checkpointing
Idea: Periodically flush all dirty pages to disk
Benefit: Limits how far back recovery must go
Trade-off: Checkpoint overhead vs recovery speed
Checkpoints are the one case where the live-transaction tracking needs its own quick scan. Instead of replaying from the start of the log, recovery scans from the last checkpoint to rebuild the table of live transactions and find where to start replaying. Without checkpoints, the forward pass starts at the beginning and the tracking is free, built as it reads.
Practice Questions
Test Your Understanding
Q1: Why does the forward pass run before the backward pass?
Q2: What if the system crashes during recovery?
Q3: How does recovery know which transactions were uncommitted at crash time?
Next
Problem Solving: The Taylor Swift Ticket Disaster → You now have the whole transaction manager: scheduling, locking, logging, and recovery. Next we put it under real load and watch where it breaks.