Correctness: Ensuring Safe Concurrent Execution
Concept. An interleaved schedule is correct if it's serializable. That is, it produces the same final database state as some serial order of the same transactions, even though the operations were interleaved.
Intuition. When Mickey and Minnie's playlist updates are interleaved at the operation level, the schedule is correct as long as the resulting Listens table looks identical to running "all of Mickey, then all of Minnie" or "all of Minnie, then all of Mickey". The per-step order can change, but the end-state must match some serial run.
Key Definitions
Foundation: Building Blocks for Correctness
To grasp how databases ensure correct concurrent execution, you need three foundational concepts:
Serializable Schedule
An interleaved schedule that mimics the outcome of some serial schedule, keeping the database consistent.
Motivation: Boosts performance
Challenge: Proving correctness requires showing the same outcome for all database values
Note: "Serializable" isn't "Serial"
• Serial: One transaction finishes before the next starts
• Serializable: Interleaved but equivalent to some serial order
Don't confuse the two!
Actions (Operations)
Transaction actions involve data access and modification through reads and writes.
Text notation: [T1.R(A), T1.W(A), T2.R(A)]
Note: Focus on R/W actions, not data modification specifics (e.g., A-=1 or B*=10)
Macro Schedules
These schedules focus on action ordering to ensure data consistency.
Contrast with Micro:
• Micro: Includes timing, IO, locks (performance focus)
• Macro: Just R/W sequence (correctness focus)
Note: Both serial & interleaved have macro/micro versions. We'll call them "schedules," adding descriptors for clarity when needed.
Conflicts: The Heart of Concurrency Control
Conflicts occur when transactions compete for the same data. Understanding them is crucial for correctness:
Conflicting Actions
Pairs of actions from different concurrent transactions where:
- Both actions involve the same data item
- At least one action is a write
Examples:
• T1.R(X), T2.W(X) are conflicting
• T1.W(X), T2.R(X) are conflicts
• T1.W(X), T2.W(X) conflict
Note: "conflicting actions," "conflicts," "conflict" all mean the same thing
Conflict Graph
A directed graph representing conflicts between transactions in an interleaved schedule.
Structure:
• Nodes represent transactions
• Directed edge from T1→T2 if T1's action conflicts with and precedes T2's action
Motivation: A simple data structure to model and analyze conflicts
Conflict-Serializable (CS) Schedules
Schedules where conflicting actions are ordered as in some serial execution.
Key Property: A schedule is conflict-serializable if its conflict graph is acyclic
Critical Point: Must be equivalent to at least one serial schedule
Motivation: The database can choose any valid serial ordering that respects conflicts
Cycle Problem: If a cycle exists, serial execution without violating conflict order is impossible
How to think:
• What creates conflicts? Writes!
• Can we find any serial order that respects these conflicts?
The Three Conflict Types
Every conflict between two concurrent operations falls into one of three buckets, defined by which operation reads vs writes the shared item. The matrix below shows how each pair behaves.

Read–Write (R–W)
T1 reads X, then T2 writes X. T1 saw the "before" value; if T1 is later compared against the "after" value, it's stale.
Write–Read (W–R)
T1 writes X, then T2 reads X. T2 sees T1's uncommitted (or in-flight) value, a "dirty read".
Write–Write (W–W)
T1 writes X, then T2 writes X. The first write is overwritten; the lost-update problem.
All three create directed edges in the conflict graph. Read–Read does NOT create a conflict; two reads of the same item commute, so they can swap order safely.
Refresher on Graph Algorithms
Understanding conflict graphs requires basic graph concepts. Here's a quick review of key algorithms used in conflict-serializability analysis.
Cyclic vs Acyclic Graphs
Key distinction for determining conflict-serializability:

Acyclic Graph (DAG): No cycles. You can traverse without looping back to a node you've already visited.
Cyclic Graph: Contains a cycle. At least one path returns to its starting node.
CS Implication: Only acyclic conflict graphs represent conflict-serializable schedules.
Topological Sort
Algorithm to find a linear ordering of nodes in a directed acyclic graph:

Definition: An ordering where for every edge A → B, A comes before B in the line-up.
Key Property: DAGs can have multiple valid topological orderings.
CS Application: Each valid topological ordering represents a serial schedule equivalent to the conflict-serializable schedule.
Practical View: Topological sorting is like dressing. Socks before shoes, pants before belt. If your graph says "shoes before socks", you have a cycle, and you're in for an uncomfortable day.
How to Test for Conflict-Serializability
The key question: How do we determine if a schedule is conflict-serializable? The answer is algorithmic.
The CS Algorithm: Build Graph → Check Cycles
Simple 3-step test: Turn any schedule into a conflict graph and check for cycles
Step 1: Create nodes for each transaction
Step 2: Add directed edges for each conflict (Ti conflicts with and precedes Tj)
Step 3: Check for cycles
Acyclic graph: Schedule is CS (topological sort gives valid serial orders)
Cycle exists: Schedule is NOT CS (impossible to serialize)
Why This Works: Each topological ordering represents a valid serial schedule equivalent to the original schedule
Reality: What Databases Actually Do
Databases don't check CS after the fact. Instead, they prevent problematic schedules proactively:
Database Strategy:
• Use locking protocols (like 2PL) to control operation order
• Block transactions until it's safe to proceed
• Guarantee only CS schedules can occur
Example: If T1 holds a lock on A, T2 must wait to access A
→ Prevents problematic interleavings before they happen
No Runtime Analysis Needed: The locking protocol ensures that any schedule that actually executes will pass the CS test
For more depth: Transaction Scheduling & Reordering Rules
Example 1: Concert Ticket Booking
Let's apply these concepts to a real scenario with 3 transactions and 2 shared variables.
Setup: The Scenario
Scenario
Concert venue with 2 sections. Three customers simultaneously try to book tickets during a high-demand sale.
Shared Variables:
• A: VIP section tickets (initially: 10)
• B: General section tickets (initially: 22)
Transaction Actions
Each customer performs specific booking operations on the shared ticket counters.
T2: R(A), R(B), W(B) - Checks for A, then books B
Expected Results
After all transactions complete successfully, the final ticket counts should be consistent.
Final Values:
• A: 9 tickets
• B: 20 tickets
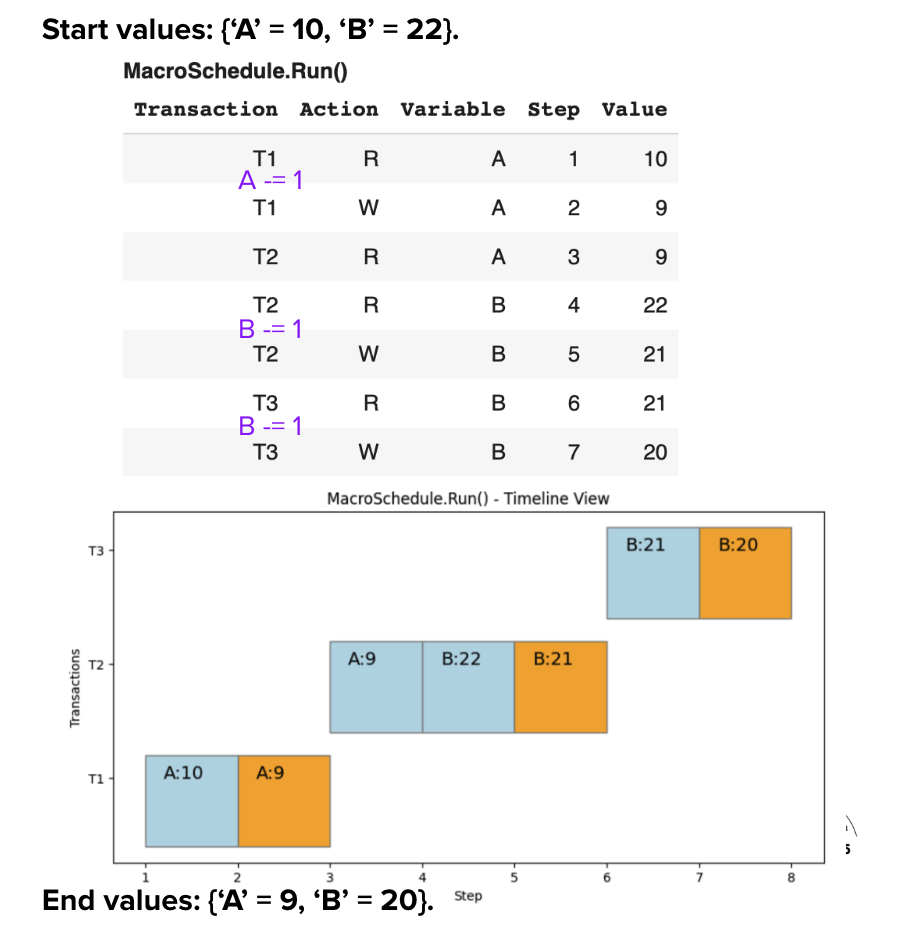
Serial Schedule S1: T1 → T2 → T3
Execution Analysis
The serial schedule guarantees correctness by running transactions one at a time:
Execution Flow:
1. T1 completes: A=9, B=22
2. T2 completes: A=9, B=21
3. T3 completes: A=9, B=20
Properties: No conflicts • Predictable • ACID maintained
Serial Schedule Guarantee: Complete isolation ensures correctness but at the cost of performance (48 time units, no parallelism).
Conflict Identification
Conflicts arise even in Serial schedules when shared variables are involved.

Conflict Analysis
Example Conflicting Action Pairs:
- T1.W(A) ↔ T2.R(A) - Write-Read conflict on A (purple)
- T2.W(B) ↔ T3.W(B) - Write-Write conflict on B (blue)
- 4 total conflicts to track in our analysis
Key Insight: Conflicts create a chain: T1 → T2 → T3
Conflict Graph Construction
Step-by-Step Process:
- Create Nodes: T1, T2, T3 (one per transaction)
- Add Edges: For each conflict, draw edge from first → second
- Check Cycles: If acyclic → Conflict-Serializable
Result: Acyclic Graph • No cycles • CS Schedule • Equivalent to T1→T2→T3
Example 2: Interleaved Schedule Analysis
Let's explore what happens when we interleave transactions. We'll examine two different interleaved schedules to understand the difference between conflict-serializable and non-conflict-serializable schedules.
Schedule S1': Our First Interleaved Schedule
Consider S1', our 1st interleaved schedule. We can interleave the transactions while preserving correctness.
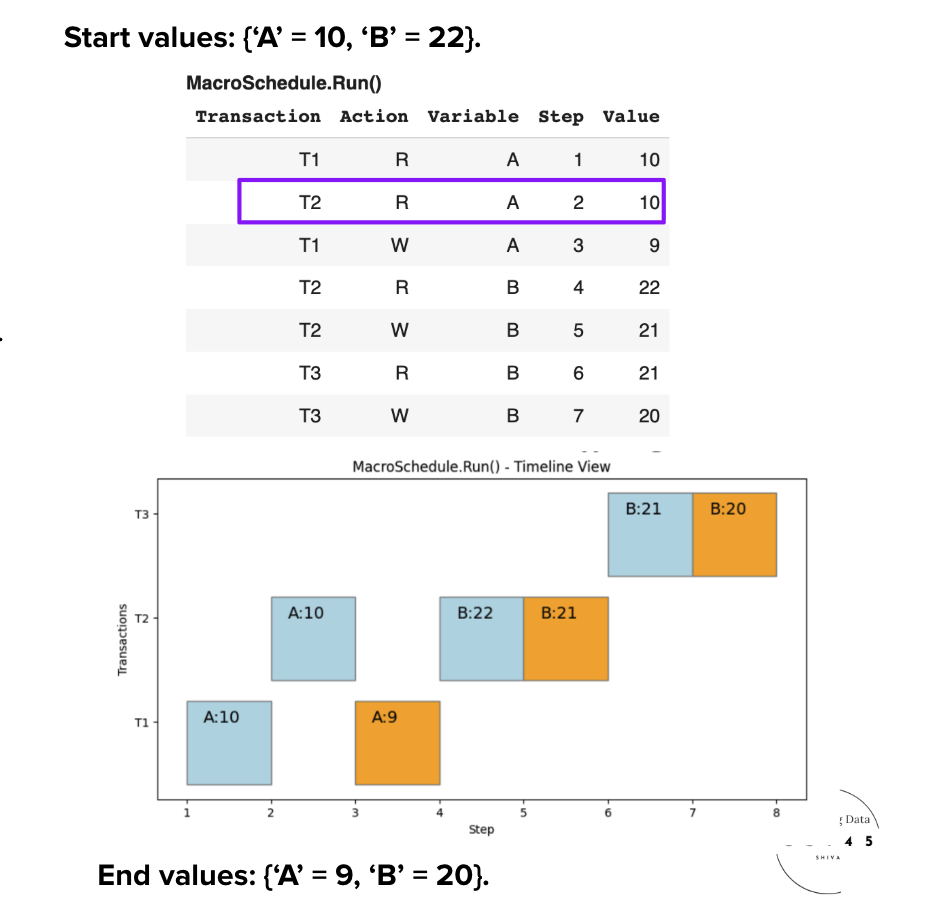
Conflicts Identified
We compute the conflicts and build the Conflict Graph:
• Various Read-Write and Write-Write conflicts
• Notable: B-(#4, #7) from T2 and T3
• 4 total conflicts across all transactions
Insight: The conflicts create dependencies between transactions that must be respected.
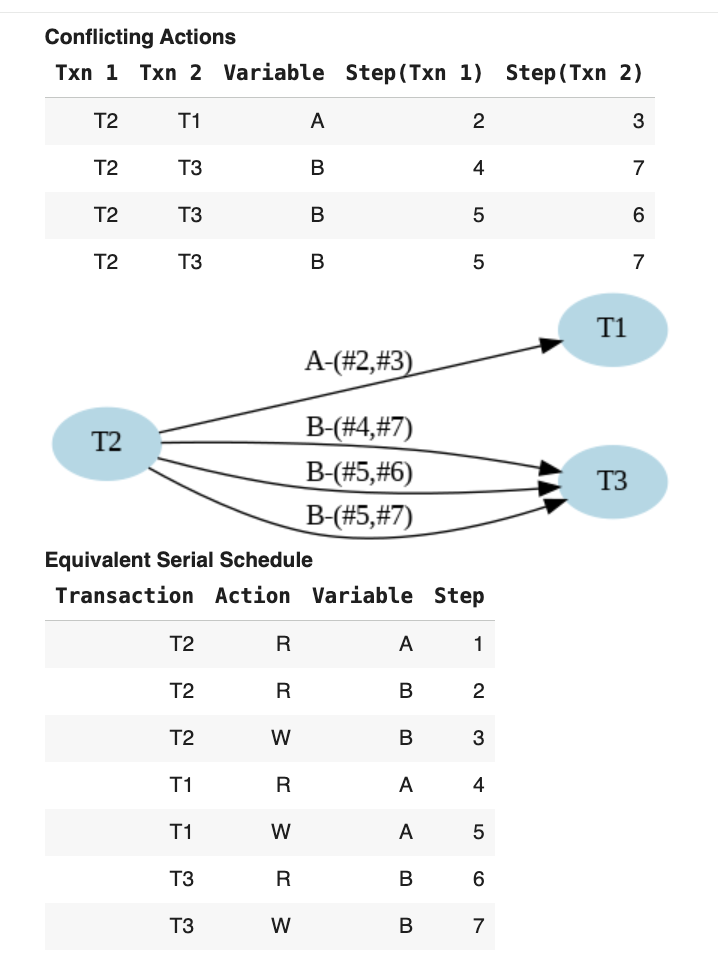
Graph Analysis
We see edges for each conflict in the Conflict Graph:
Acyclic Graph: No cycles detected
Conflict-Serializable: CS Schedule
Multiple Valid Orders: T2→T1→T3 OR T2→T3→T1
Why Both Work: Both are valid topological orderings, meaning either serial execution produces equivalent results.
S1' Takeaway: Acyclic conflict graph guarantees correctness while allowing multiple valid orderings and performance gains through interleaving.
Schedule S2': Our Second Interleaved Schedule
Consider S2', an interleaved schedule. This demonstrates what happens when interleaving creates problematic conflicts.
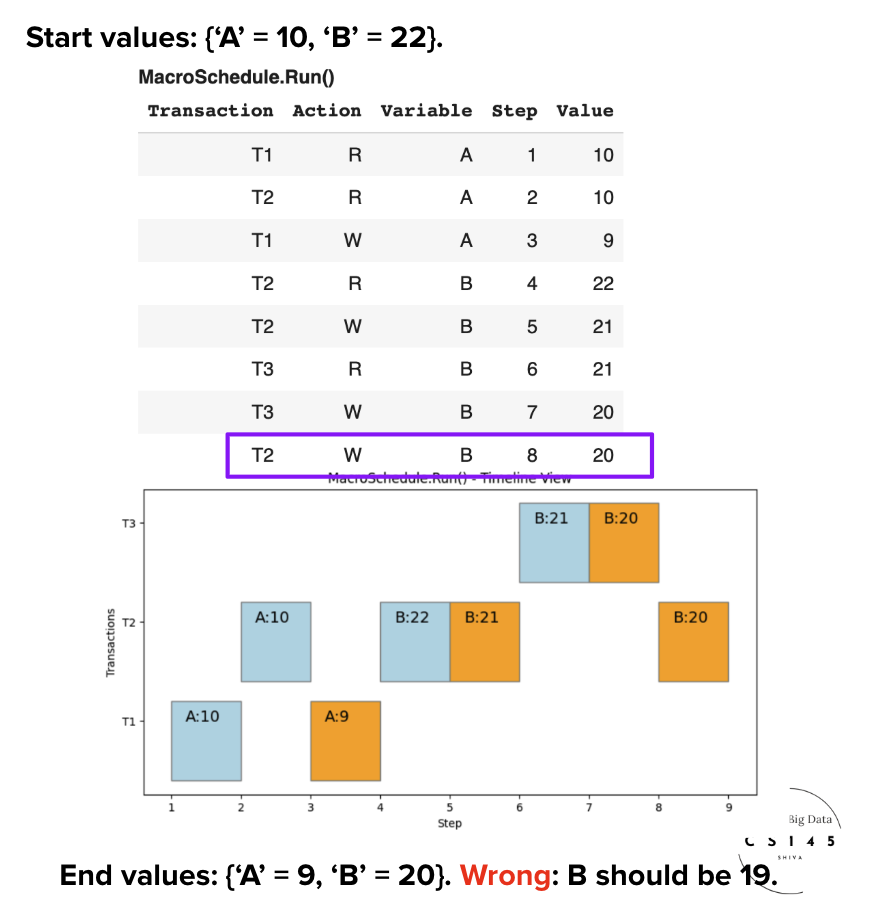
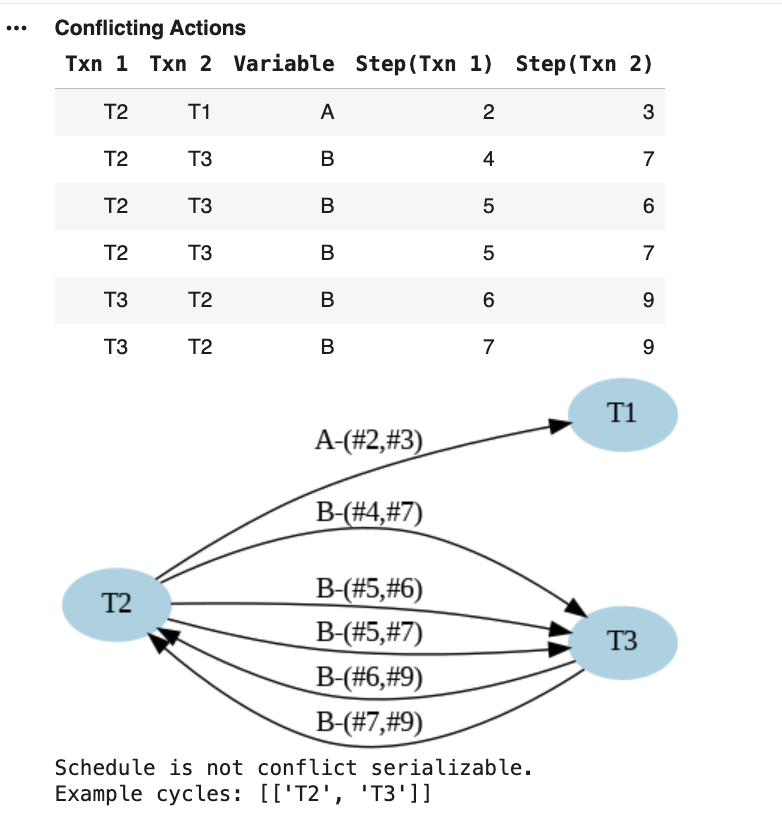
Conflicts Identified
We compute the conflicting actions and the Conflict Graph:
• Multiple Read-Write and Write-Write conflicts
• Critical Issue: Conflicts create circular dependencies
• Cycle detected between T2 and T3
Warning: The conflict pattern creates dependencies that cannot be satisfied by any serial ordering.
Graph Analysis
The Conflict Graph reveals the fundamental problem:
Cyclic Graph: Cycle between T2 and T3
NOT Conflict-Serializable: Not a CS Schedule
No Valid Serial Order: Cannot find equivalent serial execution
The Problem: T2 must precede T3 AND T3 must precede T2 - impossible!
S2' Takeaway: Cyclic conflict graph means the schedule is NOT conflict-serializable and cannot be equivalent to any serial execution.
Important Distinction: CS vs Serializable
A non-CS schedule may still be a serializable schedule, but it's often hard to prove.
The Challenge: To prove serializability, we must show that for every possible data value, the schedule produces the same outcome as some serial schedule.
The Guarantee: However, a CS schedule will always be a serializable schedule.
Practical Implication: CS is a sufficient (but not necessary) condition for serializability.
How 2PL Guarantees Conflict-Serializability
Conflict graphs tell us when a schedule is correct. The conflict-graph test from earlier (a schedule is conflict-serializable if and only if its conflict graph is acyclic) is the foundational result. But running that test on every executed schedule would be expensive. Two-Phase Locking is the protocol that ensures the schedules a database actually produces always pass that test, with no runtime check needed.
Theorem. Every schedule produced by transactions that obey 2PL is conflict-serializable.
Optional: Why it works (case-analysis proof)
2PL forces every conflict between any two transactions T₁ and T₂ to resolve in the same direction in the conflict graph.
- Each transaction has a growing phase (acquires only) and a shrinking phase (releases only). The first unlock marks the boundary.
- Suppose T₁ and T₂ conflict on shared items A, B, C, … (any combination of R-W, W-R, W-W conflicts on the same item).
- For T₁ to access A, it must hold the lock on A. T₂ accessing the same A means either T₂ hasn't acquired A yet (T₂ still in its growing phase) or T₂ already released A (T₂ already in its shrinking phase).
The key consequence. If T₁ accesses A before T₂ on any conflicting item, T₁ must access every shared item before T₂. Why? If T₁ accessed A first but accessed B second, T₁ would have had to release the lock on A and later acquire the lock on B. That's release-then-acquire, which violates 2PL.
So all conflicts between any pair of transactions point in the same direction: T₁ → T₂ for all of them, or T₂ → T₁ for all of them, never both. No two-transaction cycle is possible. Generalizing across all pairs in the schedule: the conflict graph is acyclic, and by the iff result above, the schedule is conflict-serializable.
Sufficient, not necessary. 2PL is a sufficient condition for CS. Every 2PL schedule is CS, but not every CS schedule comes from 2PL. Some CS schedules require release-then-reacquire patterns that 2PL forbids. The trade-off: 2PL gives up a slice of theoretical flexibility for a simple, runtime-cheap rule that produces only safe schedules. This is why production databases overwhelmingly use 2PL or its variants. See Two-Phase Locking for the protocol mechanics and Strict 2PL's cascading-abort guarantee.
