Recovery Post-Crash 💥
🔄 Bringing the Database Back to Life
How databases recover from crashes using the WAL log to restore consistency
The moment of truth: UNDO incomplete transactions, REDO committed ones
The Crash Scenario 🚨
When a database crashes, it leaves behind:
-
Committed transactions that may not be fully written to disk
-
Partially complete transactions that were active during the crash
-
WAL log with the complete history of all changes
The recovery process must:
-
Analyze the WAL log to understand what happened
-
REDO finished (committed) transactions to ensure durability.
-
UNDO incomplete transactions to ensure atomicity
[Optional]: Detailed Notes on Steps 2 and 3
In Step 2: we just repeat every single action in the WAL from top to bottom (before the DB crashed). Cases to consider:
-
If there is a COMMIT row for the transaction in WAL, the recovery process will REDO the changes.
-
If there is an ABORT row for the transaction in WAL, the recovery process will do exactly what the transaction had done -- first do (REDO) all the changes and then UNDO the changes.
In Step 3: for the transactions with no COMMIT/ABORT in the WAL, we treat them as ABORTs, we will UNDO that transaction's changes.
Potential Optimizations: some DBs will optimize the REDO-then-UNDO step for ABORT transactions. (needs some good algorithms for performance reasons). For example, if the transaction is a long-running transaction for 1 million variables, we'll be smarter about REDOING and UNDOING the changes rather than waste IOs blindly.
When Machine (or disk or network) Crashes
Just Before Crash

Just After Crash

What we see after crash:
-
Some changes are in the database (from buffer flushes)
-
Some committed work might be missing (still in RAM when crashed)
-
Some incomplete work might be present (on disk but not committed)
-
WAL log has everything we need to fix this mess!
🔍 Analysis Phase
The Recovery Process
The recovery algorithm in action:
-
Phase 1 - Analysis: Read WAL to build transaction table
-
Phase 2 - REDO: Replay all changes (even unfinished ones) to reconstruct state
-
Phase 3 - UNDO: Roll back unfinished transactions
✅ REDO Phase
❌ UNDO Phase
After Recovery Complete
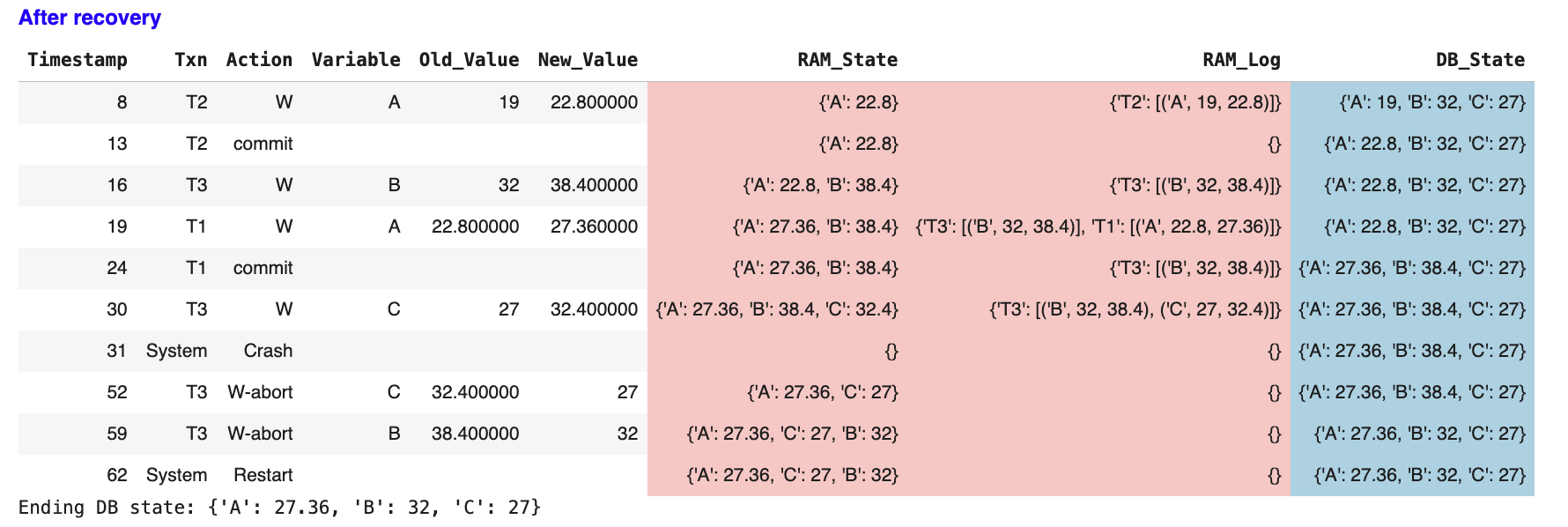
The final state:
-
✅ All committed transactions are fully applied
-
❌ All uncommitted transactions are completely removed
-
🎯 Database is in a consistent state
-
Ready to accept new transactions
💡 Why This Works
The WAL is the source of truth!
- It has the complete history of all changes
- It has both old and new values for every change
- It's written durably before any actual data changes
- Even if the database is corrupted, WAL can rebuild everything
Recovery Guarantees 🛡️
What Recovery Ensures
- Atomicity: Transactions are all-or-nothing
- Durability: Committed work survives crashes
- Consistency: Database rules are preserved
- Repeatability: Recovery is deterministic
What Recovery Costs
- Time: Can take minutes to hours for large databases
- I/O: Must read entire WAL since last checkpoint
- Availability: Database offline during recovery
- Complexity: Requires careful implementation